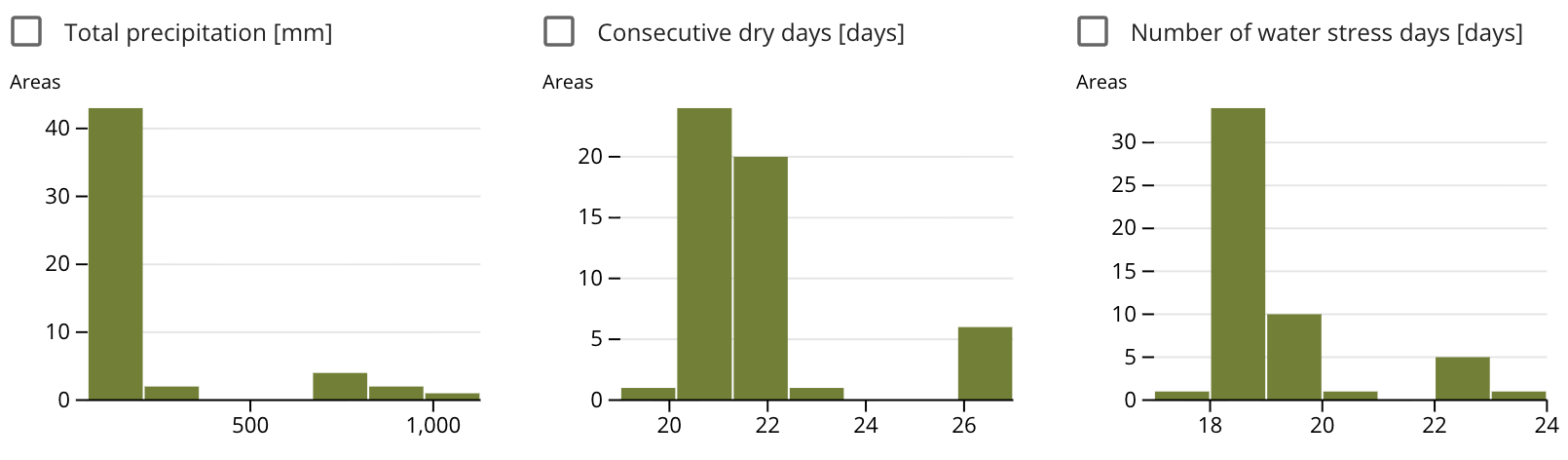
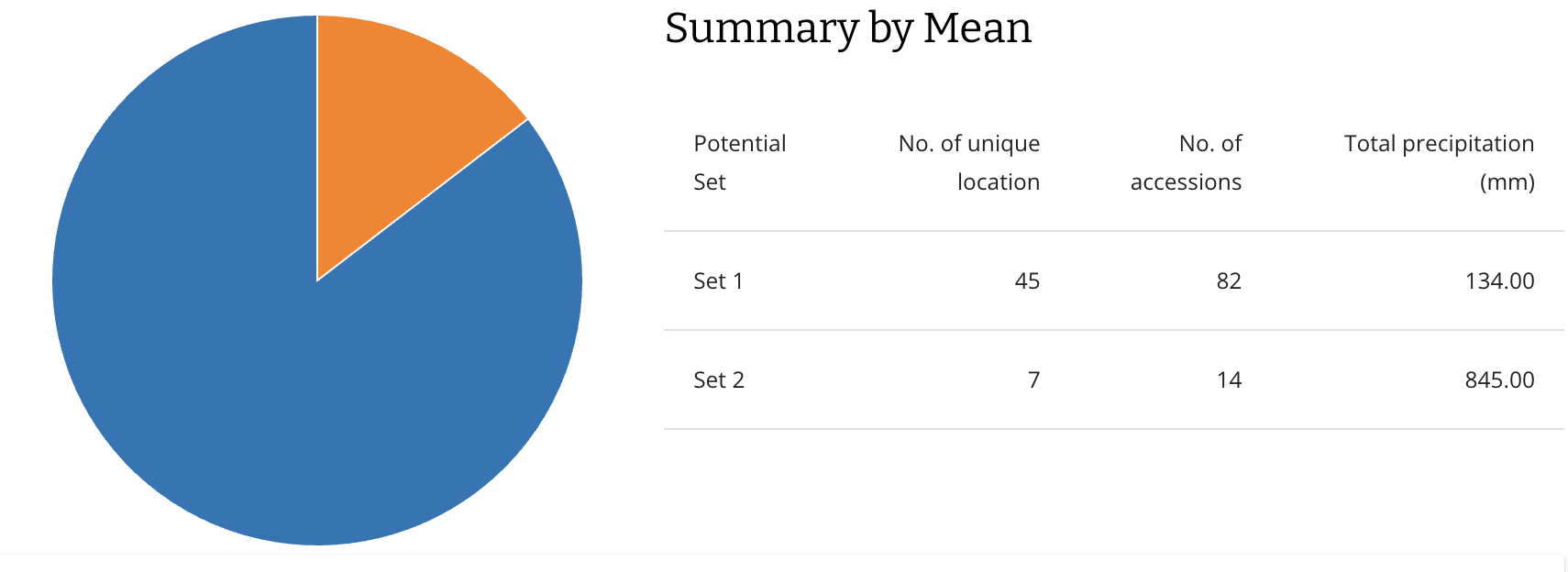
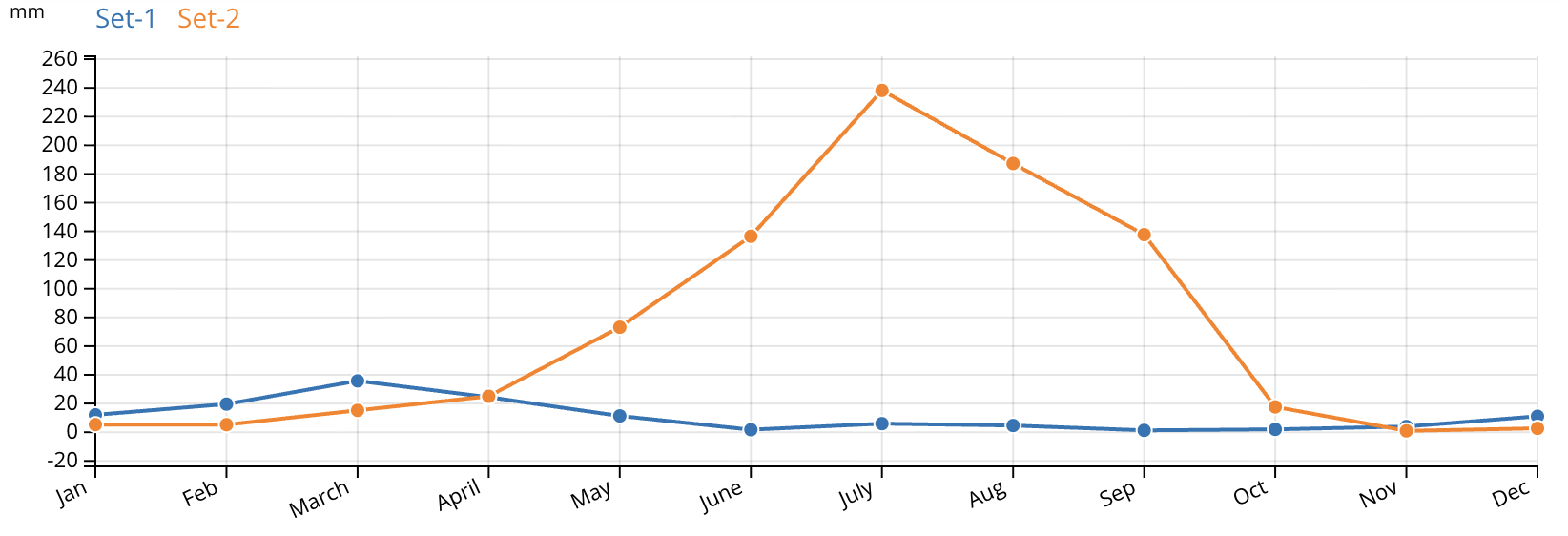
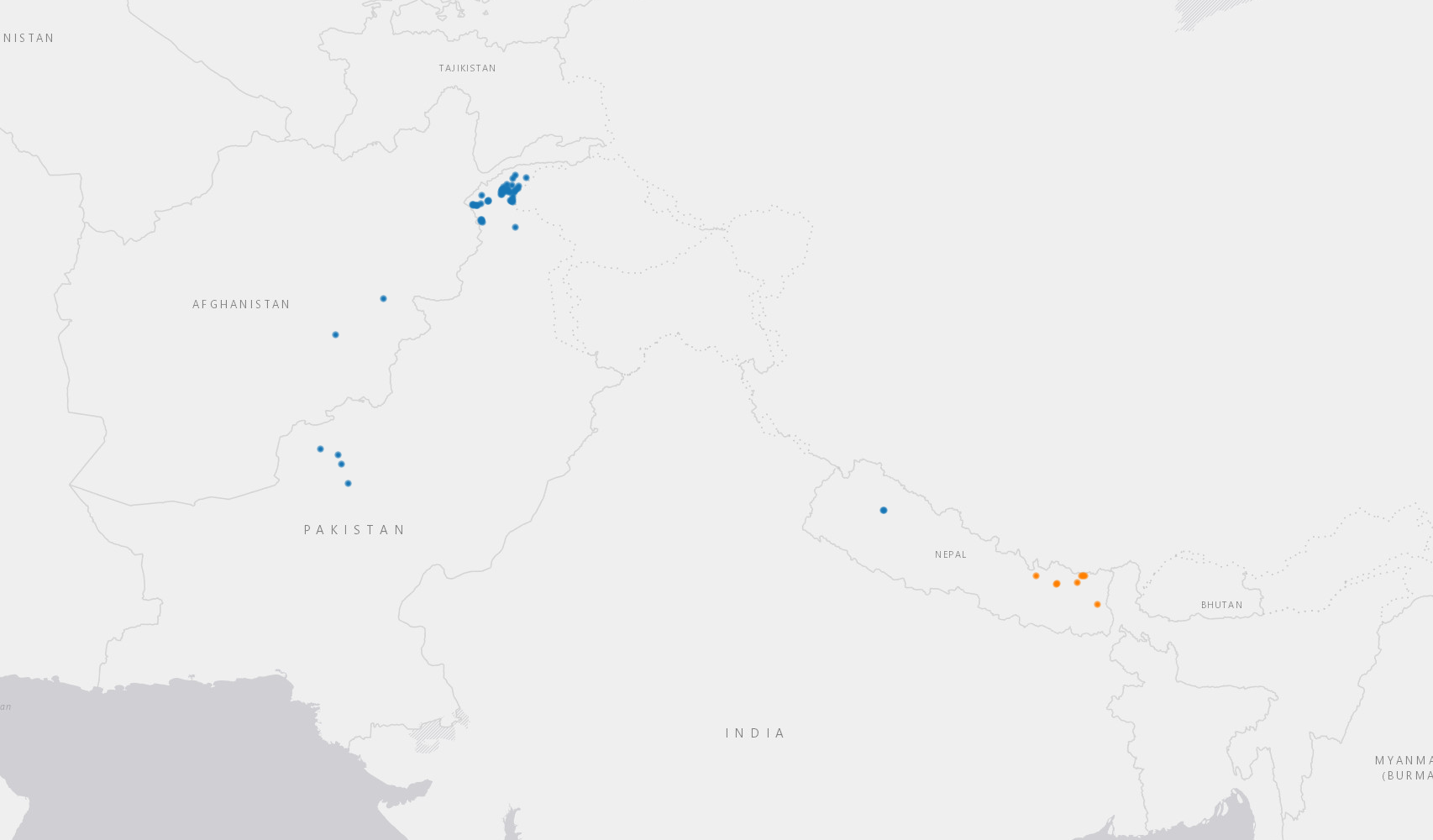
Many thanks to long-time friend-of-the-blog Dr Colin Khoury for this latest contribution.
Conservation gap analysis using Geographic Information System (GIS) tools relies on several sources of biological and environmental data, including in situ species occurrences and climatic and other environmental variables used to conduct species distribution modeling, as well as passport data from ex situ collections. While species distribution modeling and associated methods had been in development since at least the 1970s (see Rebelo, 1994 and Booth et al., 2013), the widespread use of these tools was not possible until such biological and environmental data were more easily and widely accessible, for example through GBIF, WorldClim, and Genesys.
Genebank scientists, often in collaboration with academic researchers, began to apply available GIS-based tools to PGRFA conservation around the turn of the century, proceeding to develop new methods, software, and datasets (for early examples, see Guarino, 1995; Greene and Guarino, 1999; Guarino et al., 2002). Global climate datasets were compiled at relatively high spatial resolution (e.g., Hijmans et al., 2005), providing key inputs for species distribution modeling. Current distribution models for plant genetic resources began to be calculated, for example for wild relatives of potatoes and peanuts, while future distributions under climate change also began to be modeled, for example for wild peanuts, potatoes, and cowpeas. Field collecting was informed through these tools, for example for wild clover and wild chile pepper expeditions.
The focus on wild relatives of food and agricultural crops was not haphazard. These species were receiving increasing conservation attention at the time in recognition of their value as genetic resources for crop breeding, and because many wild relatives were known to be threatened in their natural habitats and were underrepresented in ex situ repositories. International conservation targets for crop wild relatives had been set at the Convention on Biological Diversity (CBD) (for 2011 to 2020 and again for 2020 to 2030) and in the United Nations Sustainable Development Goals (SDGs) (for 2015 to 2030). At the same time, species distribution modeling methods had primarily been developed for wild species, i.e. taxa whose distributions are mainly driven by climatic, edaphic, and other environmental factors, rather than human preferences (which are more difficult to model), therefore the application of these methods to crop wild relatives was relatively straightforward and a logical starting point for the agricultural research community.
Programs such as DIVA-GIS and FloraMap were created to make the methods more accessible to researchers and practitioners without extensive GIS experience and computing power. Such efforts continue, for example by CAPFITOGEN.
Through an international genebank initiative called the Global Public Goods Project II, run from 2007-2010, the distributions of the wild relatives of ten CGIAR mandate crops were mapped, with priorities for further collecting for ex situ conservation identified. A major milestone of that project was the publication of a standardized, replicable gap analysis methodology for the ex situ conservation of crop wild relatives, which made use of herbarium and other biodiversity observations acquired through GBIF and other sources, as well as genebank passport data, and which embraced recent advancements in species distribution modeling methods.
Continue reading “A brief history of gap analysis for crop diversity conservation”