- Genetic Diversity of Cultivated Lentil (Lens culinaris Medik.) and Its Relation to the World’s Agro-ecological Zones. 352 accessions, 54 countries, 3 agro-ecological groups (South Asia, Mediterranean, N temperate) in USDA collection.
- Association mapping of seed and disease resistance traits in Theobroma cacao L. 6 and 1 markers, respectively, based on 483 unique trees in the International Cocoa Genebank, Trinidad (ICGT).
- Historic translocations of European larch (Larix decidua Mill.) genetic resources across Europe – A review from the 17th until the mid-20th century. Humans have moved material to areas outside its native distribution, and have mixed up genetically distinct populations in some places.
- Insights into the Genetic Relationships and Breeding Patterns of the African Tea Germplasm (Camellia sinensis (L.) O. Kuntze) Based on nSSR Markers and cpDNA Sequences. African material groups according to where it was bred.
- First the seed, next the smolt? Will salmon farmers learn the right lessons from plant biotechnology? I bet not.
- Geographic patterns of phenotypic diversity in sorghum (Sorghum bicolor (L.) Moench) landraces from North Eastern Ethiopia. There aren’t any. Patterns, that is.
- Subgenome parallel selection is associated with morphotype diversification and convergent crop domestication in Brassica rapa and Brassica oleracea. Similar heading and tuberous morphotypes in the two species are due to parallel selection on genes that diverged after duplication event.
- Assessing the Cost of Global Biodiversity and Conservation Knowledge. Golly, it’s expensive!
- Sixteen years of change in the global terrestrial human footprint and implications for biodiversity conservation. Human footprint hasn’t increased by as much as might be feared, but still extends over 75% of world’s land surface. Let the mashing up with crop wild relatives hotspots begin!
Brainfood: Ryegrass genome, Pest distributions, German oregano, Pápalos distribution, Chinese pea, Dutch cattle, Animal biobanking, Legumes everywhere, Crop diversification in China, Asian fermentation
- An ultra-high density genetic linkage map of perennial ryegrass (Lolium perenne) using genotyping by sequencing (GBS) based on a reference shotgun genome assembly. Zzzzzzz.
- Future Risks of Pest Species under Changing Climatic Conditions. We’re doomed.
- Antioxidant capacity variation in the oregano (Origanum vulgare L.) collection of the German National Genebank. It’s huge. Fantastic. The best variation you’ve ever seen, I guarantee it.
- The distribution of cultivated species of Porophyllum (Asteraceae) and their wild relatives under climate change. New one on me.
- Biodiversity analysis in the digital era. Using the Atlas of Living Australia as an example.
- Large-scale evaluation of pea (Pisum sativum L.) germplasm for cold tolerance in the field during winter in Qingdao. 214 out of 3672, mainly coming from, wait for it, the winter production regions.
- Conservation priorities for the different lines of Dutch Red and White Friesian cattle change when relationships with other breeds are taken into account. 5 out of 7 genetic lines don’t need to be conserved.
- Domesticated Animal Biobanking: Land of Opportunity. “…journals should apply the same standard to samples and associated data, as they currently apply to molecular data, in terms of storage in formalized repositories prior to publication.”
- Neglecting legumes has compromised human health and sustainable food production. Includes nice summary of genebank holdings, using Genesys as a source of information.
- Crop Diversity and Land Simplification Effects on Pest Damage in Northern China. Diversity to the rescue. But…
- Ethnic Fermented Foods and Alcoholic Beverages of Japan. Just one chapter in a whole book on fermentation in Asia.
Agroforestry around the world
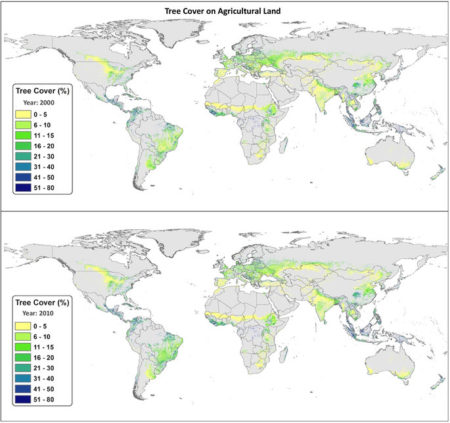
I’ve been looking for an excuse to play around with the Database of Places, Language, Culture and Environment (D-PLACE), which “contains cultural, linguistic, environmental and geographic information for over 1400 human ‘societies’”. It finally arrived today, in the form of a monumental study of carbon sequestration on farmland in Nature. The authors used remote sensing and fancy spatial modelling to work out the amount of tree cover, and hence the levels of biomass carbon, on agricultural land around the world. This is the global map they got for % tree cover in 2000 and 2010.
I was curious to see whether one could predict the areas of highest tree cover (or highest biomass C) from the much coarser data on agriculture that D-PLACE brings together from ethnographic studies. This is what the distribution of “major crop type” looks like, from D-PLACE.
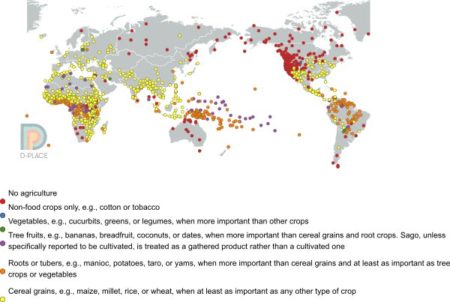
So the answer is no, I guess. It’s difficult to see any association between the amount of trees on farms and the main types of crops grown there, at least just by eyeballing the maps. There may be a hint of a preference for roots and tubers, but nothing really jumps out. I’ll keep playing though, there’s a whole range of cultural and ecological variables you can tweak.
Brainfood: China cereal yield, US soybean breeding, Breadfruit genomics, Field app, Urban ag, Rose breeding, Strawberry cryo, Global biodiversity loss, Oceania bananas, Vegetable breeding, Badass Chinese sheep
- Patterns of Cereal Yield Growth across China from 1980 to 2010 and Their Implications for Food Production and Food Security. There has been yield stagnation over about 50% of total area of rice and maize, 15% of wheat.
- Genomic signatures of North American soybean improvement inform diversity enrichment strategies and clarify the impact of hybridization. 579 soybean varieties released 1940-2009 fall into 3 maturity groups, the overall diversity of which is not too different from the diversity of the ancestor landraces.
- Low-Coverage, Whole-Genome Sequencing of Artocarpus camansi (Moraceae) for Phylogenetic Marker Development and Gene Discovery. There’s been a whole genome duplication in Artocarpus.
- ColectoR, a Digital Field Notebook for Voucher Specimen Collection for Smartphones. So many of these things around.
- Potential ecosystem services of urban agriculture: a review. Important at local scale, not so much at global scale.
- Nineteenth century French rose (Rosa sp.) germplasm shows a shift over time from a European to an Asian genetic background. Ah, the lure of the exotic; 19 genetic groups, not corresponding to horticultural groups.
- Cryopreservation of in vitro shoot tips of strawberry by the vitrification method — establishment of a duplicate collection of Fragaria germplasm. The German national collection, including wild relatives, is a bit safer.
- Has land use pushed terrestrial biodiversity beyond the planetary boundary? A global assessment. Looks like it. Cross-reference with crop wild relatives?
- Traditional Banana Diversity in Oceania: An Endangered Heritage. Out of New Guinea…
- The contribution of international vegetable breeding to private seed companies in India. Vegetable breeding by AVRDC still has a role as R&D shifts to the private sector, but it’s different to what it was.
- Whole-genome sequencing of native sheep provides insights into rapid adaptations to extreme environments. Genomes of 77 Chinese breeds from extreme environments reveal genes likely to be useful in extreme environments.
Nibbles: African fruits, Old apple, Ancient barley, GRAIN study, Desertification, Biodiversity loss
- ICRAF helps us understand little-understood African fruit trees.
- The apple is pretty well understood, but this one important, 200-year-old tree is dying. Tissue culture to the rescue.
- I see your 200-year-old-tree and I raise you 6000-year-old barley.
- GRAIN takes aim at FTAs.
- Desertification may not be a thing.
- Biodiversity loss is, though, right?