- The role of wild fruits and vegetables in delivering a balanced and healthy diet. Not great, until they’re domesticated.
- Maize Diversity, Market Access, and Poverty Reduction in the Western Highlands of Guatemala. Forget maize.
- Evaluation of Wild Lentil Species as Genetic Resources to Improve Drought Tolerance in Cultivated Lentil. Environment explained drought response in wild lentils better than molecular classification.
- Geographical distribution, diversity and gap analysis of East African sorghum collection conserved at the ICRISAT genebank. Both Sudans.
- Explaining the Ethiopian farmers’ perceptions on potential loss of traditional crop varieties: A principal components regression analysis. Poor farmers know more, and care more, about loss of traditional landraces.
- High-throughput sequencing of African chikanda cake highlights conservation challenges in orchids. Those are very biodiverse cakes, but not in a good way.
- Revisiting the ‘cornerstone of Amazonian conservation’: a socioecological assessment of Brazil nut exploitation. It’s actually in pretty good shape, but that doesn’t mean it can’t be improved.
- Phylogenetic Prediction of Alternaria Leaf Blight Resistance in Wild and Cultivated Species of Carrots. Look for taller material in clade A.
- Starch granule evidence for the earliest potato use in North America. S. jamesii may have been used for 10,000 years in Utah.
- Genome-Wide Association Study of Grain Architecture in Wild Wheat Aegilops tauschii. Two genetic lineages, with big differences in grain width and weight.
Brainfood: Taste breeding, Cat domestication, ITPGRFA in USA, CWR extravaganza, Ecology & ag, Brassica identification, Biodiversity monitoring, Languages, Species recovery, Benin pigeonpea
- Sensory sacrifices when we mass-produce mass produce. You need consumer-assisted selection.
- The palaeogenetics of cat dispersal in the ancient world. Two Middle-Eastern sub-populations of one sub-species contributed to domestication, at different times, and the result spread first with agriculture and then aboard ships. But we haven’t changed them in the same way we’ve changed dogs etc. You don’t say.
- U.S. ratification of Plant Treaty: benefit sharing ambiguity for plant genomics researchers does not change. But what about genomics data?
- Wading Into the Gene Pool: Progress and Constraints Using Wild Species. Introduction to the Special Section on CWR.
- Plant ecological solutions to global food security. Introduction to the Special Feature on Ecological Solutions to Global Food Security. The intersection with the above is probably here.
- A multiplex PCR for rapid identification of Brassica species in the triangle of U. Now there’s no excuse.
- Connecting Earth observation to high-throughput biodiversity data. I don’t see any reason why the same thinking couldn’t be applied to crop diversity.
- Linguistic diversity of natural UNESCO world heritage sites: bridging the gap between nature and culture. 80% of Natural WHSs intersect at least one indigenous language.
- Overcoming barriers to active interventions for genetic diversity. Embrace the hybrid by focusing on process, not form.
- Utilization and farmers’ knowledge on pigeonpea diversity in Benin, West Africa. For some reason, farmers don’t like coloured seeds.
Brainfood: Maize regeneration, Watkins collection, Jordan barley landraces, CWR in Europe, Early agriculture, Papaya knowledge, Cryo, Tree diversity, AM, Indegee, Wild beet, Early NE ag, Fire!
- Ex-situ conservation of maize germplasm from different latitudes. You can do it, but not without some genetic changes.
- High density genotyping of the A.E. Watkins Collection of hexaploid landraces identifies a large molecular diversity compared to elite bread wheat. There’s plenty of interesting variation there, as you’d expect.
- Changes in barley (Hordeum vulgare L. subsp. vulgare) genetic diversity and structure in Jordan over a period of 31 years. No significant changes in the amount of genetic diversity in landraces collected in 1981 and in 2012, but later samples more homogenous and less locally distinct.
- Crop wild relatives range shifts and conservation in Europe under climate change. We’ll need genebanks.
- Isotope evidence for agricultural extensification reveals how the world’s first cities were fed. By opening up new land, basically, and never mind the fancy agronomic practices.
- Can the Introduction of Modern Crop Varieties in their Centre of Origin Affect Local Ecological Knowledge? A Case Study of Papaya in the Yucatan Peninsula. Yes, and not in a good way.
- Cryopreserved storage of clonal germplasm in the USDA National Plant Germplasm System. It really is a system.
- A meta-analysis of molecular marker genetic datasets for eastern Africa trees supports the utility of potential natural vegetation maps for planning climate-smart restoration initiatives. But you still have to do the trials.
- Global Diversity and Importance of Mycorrhizal and Nonmycorrhizal Plants. 72% of vascular plants have them.
- Factors associated with agrobiodiversity conservation: A case study on conservation of rice varieties in Barak valley, Assam, India. More connections means more varieties.
- Crop wild relative populations of Beta vulgaris allow direct mapping of agronomically important genes. Genotyping and phenotyping of 189 wild plants along a 10 km transect allows identification of disease resistance gene in the crops.
- Near Eastern Plant Domestication: A History of Thought. The punctuated-centric view is better, according to Occam.
- Fire and plant diversity at the global scale. They’re correlated, or at least associated.
Some new germplasm databases, at least to me
Long-time readers may remember a post from 2012 summarizing some media reports of trouble at the Italian national genebank at the National Research Council (CNR), Bari. But maybe things are not as bad as were made out at the time. Or have got better.
I’ve just come across what seems to be a fairly new website for the genebank and it doesn’t give the impression of crisis. It lists 57,568 accessions from 184 genera and 834 species, which is more that was reported back in 1999 in WIEWS for ITA004, hopefully the correct code for the genebank in question (at least the address matches, if not the name of the institute). This is the geographic coverage of the collection:
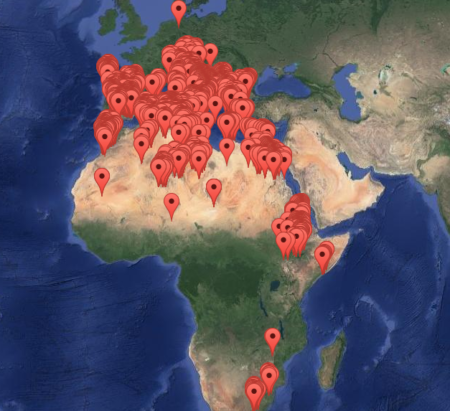
Impressive. Unfortunately, data on these accessions are not available in the European genebank database, Eurisco, and therefore they’re not in the global portal, Genesys, either. Hopefully that’s being rectified.
Since I’m on the subject of germplasm databases, I’ve also recently come across the Legume Information System, which focuses on material in the US genebanks. It has all kinds of data, but I just looked for germplasm from Italy to compare with what’s in Bari. Here’s the map for Medicago spp, showing growth habit in different colours (click on it to see it better).
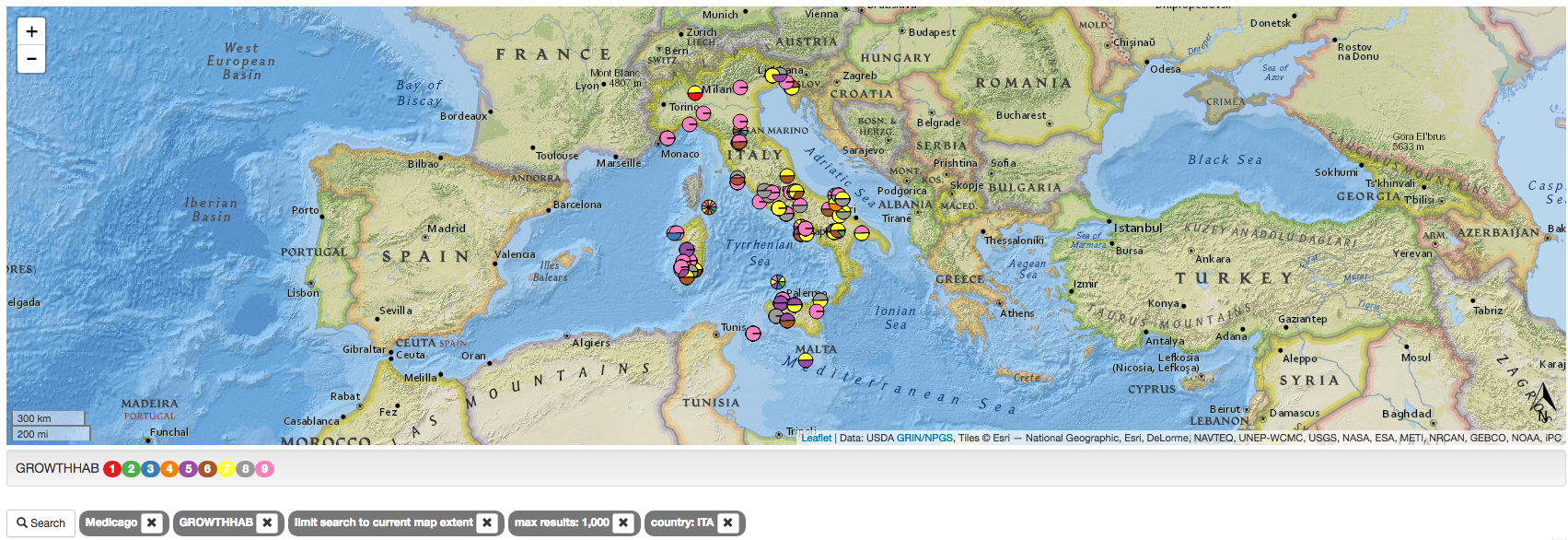
Compare and contrast with the ITA004 collection for the same species.
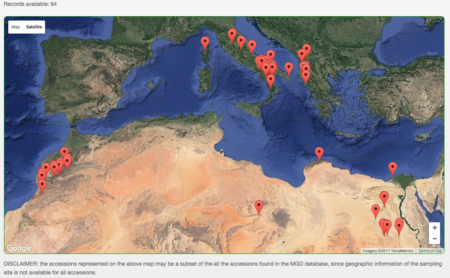
Which is why it’s a good idea to have all these data together in one place, i.e. Genesys.
Getting to grips with rice in Europe
A little more on that RiceAtlas that I blogged about a couple of days ago. I managed to download the shapefile of rice growing areas, and open it in Google Earth. I then imported the Genesys rice dataset, and zoomed in on Europe. Here’s what those two things together look like.
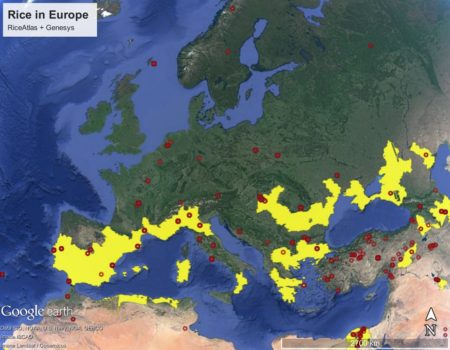
Definitely a few issues. I’m not too worried about the accessions in northern Europe. Those are probably just wrong passport data. But what about all those in Turkey which are also outside putative rice growing areas? Are those passport data mistakes too, or is RiceAtlas missing something?